The Evolution from MapReduce to YARN: Empowering Flexible Data Processing in Hadoop
The Apache Hadoop ecosystem has revolutionized the world of big data processing, enabling organizations to effectively store, process, and analyze massive amounts of data. One of the key components of Hadoop is MapReduce, a programming model and software framework that simplifies parallel processing of large datasets. However, with the evolution of Hadoop, MapReduce has given way to a more flexible and scalable framework known as YARN (Yet Another Resource Negotiator). In this blog post, we will explore the transition from MapReduce to YARN and understand the reasons behind this transformation.
MapReduce: The Initial Paradigm
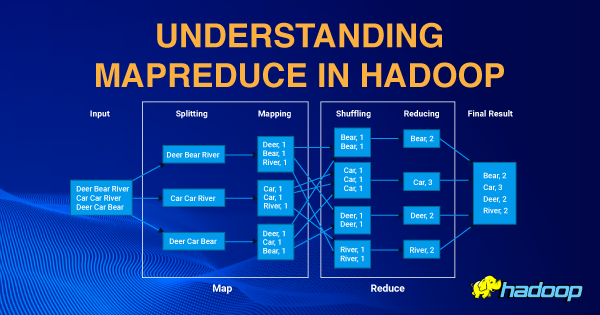
MapReduce was initially introduced by Google to process large-scale distributed datasets efficiently. It divides data processing tasks into two stages: the map stage and the reduce stage. The map stage processes the input data and produces intermediate key-value pairs, while the reduce stage aggregates the intermediate results to generate the final output. MapReduce provided a simple programming model and allowed for distributed processing across multiple nodes in a Hadoop cluster. However, it had certain limitations that hindered its flexibility and resource utilization.
The Need for a More Flexible Framework
As Hadoop gained popularity, it became evident that MapReduce had certain drawbacks that needed to be addressed. One major limitation was its static and rigid architecture, where the framework allocated resources only for MapReduce jobs. This approach made it difficult to run other types of data processing applications on the same cluster, such as interactive queries, stream processing, and graph processing. Additionally, MapReduce had limited support for multi-tenancy and resource sharing, which restricted its scalability and efficiency.
Introducing YARN: A Paradigm Shift
To overcome the limitations of MapReduce and cater to the evolving requirements of big data processing, the Apache Hadoop community introduced YARN with the release of Hadoop 2.0. YARN aimed to separate the resource management and job scheduling aspects from the core MapReduce framework, allowing for a more flexible and extensible architecture.
YARN introduced a new central component called the ResourceManager, which became responsible for resource allocation and management across the Hadoop cluster. It enabled the cluster to run multiple distributed data processing frameworks simultaneously, including MapReduce, Spark, Hive, and others. YARN’s resource management capabilities improved the overall cluster utilization and enabled better sharing of resources among different applications.
The ResourceManager delegates the actual execution of tasks to per-node NodeManagers, which are responsible for managing resources on individual nodes. This distributed architecture allows YARN to support a wide range of processing models and applications, making Hadoop a versatile platform for big data processing.
Benefits of YARN
The transition from MapReduce to YARN brought several significant benefits to the Hadoop ecosystem:
- Flexibility: YARN allowed Hadoop to support a variety of data processing frameworks, making it a more versatile platform for different workloads.
- Resource Management: YARN improved resource utilization by enabling the sharing of cluster resources among various applications, leading to better cluster efficiency and cost savings.
- Scalability: YARN’s distributed architecture enabled seamless scaling of the cluster to handle larger workloads and accommodate more users.
- Multi-tenancy: YARN introduced support for multi-tenancy, enabling different users or groups to securely share the same Hadoop cluster while maintaining isolation and resource guarantees.
Enhanced Performance and Efficiency
YARN introduced a more efficient and optimized resource management system, which improved the overall performance of data processing applications. It enabled finer-grained resource allocation, allowing tasks to be executed in a more optimized manner. This finer control over resources resulted in better utilization of cluster resources, leading to faster and more efficient data processing.
Level Up Your Programming Skills with these 11 Engaging Coding Games
Support for Diverse Workloads
With YARN, Hadoop became a platform that could support a wide range of data processing workloads. Previously, MapReduce was primarily designed for batch processing, but YARN opened up the possibilities for running real-time streaming, interactive queries, machine learning, and graph processing frameworks such as Apache Spark, Apache Flink, Apache Tez, and Apache Storm. This flexibility allowed organizations to choose the right tool for their specific needs, unlocking new capabilities for big data analytics.
Improved Cluster Utilization
YARN’s ability to support multiple frameworks and applications on a single cluster significantly improved cluster utilization. Before YARN, clusters were often underutilized because MapReduce jobs typically consumed resources only during their execution time. With YARN, other applications and frameworks could coexist on the same cluster, making better use of available resources and reducing idle time.
Dynamic Resource Allocation
YARN introduced the concept of dynamic resource allocation, which allows applications to request additional resources based on their needs. This feature is particularly beneficial for applications with varying resource requirements over time. Dynamic resource allocation enables better scalability and responsiveness, ensuring that applications have the necessary resources to handle increasing workloads or sudden bursts of data processing demand.
Ecosystem Integration
YARN seamlessly integrates with the broader Hadoop ecosystem, enabling easy integration with various tools and technologies. It provides APIs and interfaces that allow developers to build applications on top of YARN and leverage its resource management capabilities. This integration further enhances the capabilities of Hadoop and promotes a vibrant ecosystem of data processing frameworks and applications.
The transition from MapReduce to YARN marked a significant milestone in the evolution of the Hadoop ecosystem. YARN’s flexible architecture and resource management capabilities addressed the limitations of MapReduce and allowed Hadoop to become a more versatile and scalable platform for big data processing. With YARN, organizations can run a wide range of data processing frameworks and applications on the same cluster, improving resource utilization and accommodating diverse workloads. As the big data landscape continues to evolve, YARN remains a crucial component in enabling organizations to derive valuable insights from their ever-increasing volumes of data.