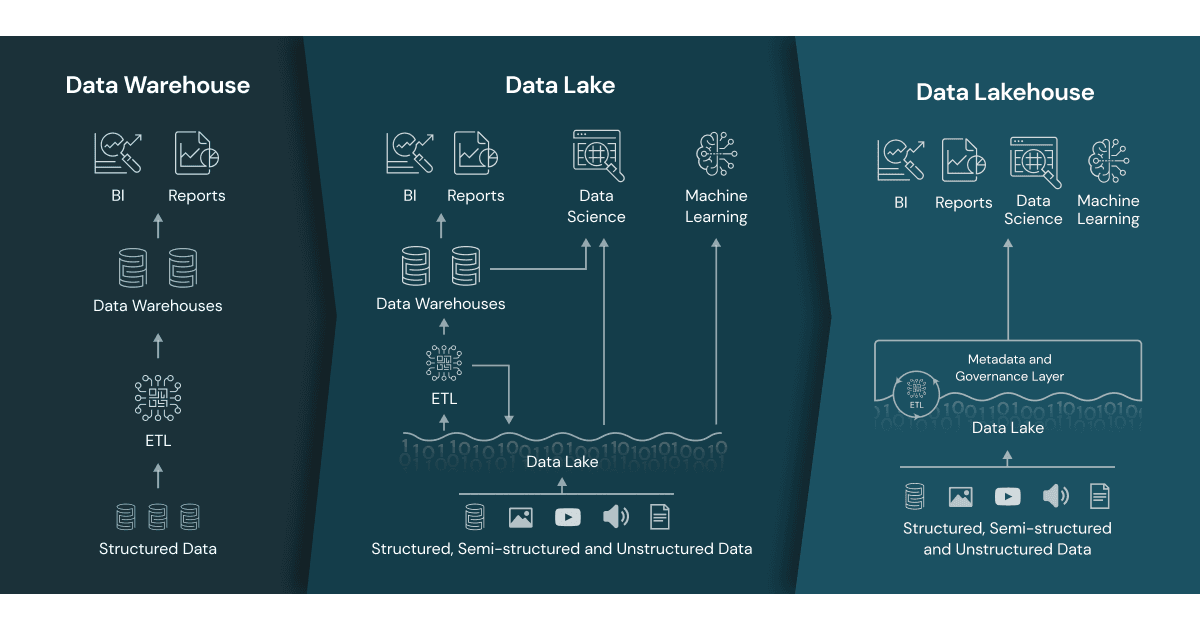
Serverless Vs Classic Compute Resources in the Databricks: The Databricks Lakehouse Platform is a powerful and versatile solution for managing data lakes, enabling data engineers and data scientists to efficiently process, analyze, and derive insights from vast amounts of data. Within this platform, there are two primary modes for compute resources: serverless and classic. In this blog post, we will delve into the distinctions between these two modes, highlighting the ways in which serverless compute resources differ from classic compute resources.
Serverless Compute Resources
1. Flexibility and Scalability
One significant advantage of serverless compute resources in the Databricks Lakehouse Platform is their inherent flexibility and scalability. With serverless, users are not tied to predefined clusters or nodes. Instead, they can leverage auto-scaling capabilities to ensure that the right amount of computational resources is allocated for the task at hand. This elasticity allows for more efficient resource utilization and cost savings since users only pay for what they use.
2. Simplified Management
Serverless compute resources simplify the management overhead. Users do not need to provision, configure, or manage clusters manually. The platform takes care of resource provisioning and scaling based on the workload’s requirements. This abstraction of infrastructure management allows data teams to focus on their core tasks of data analysis and processing without being burdened by infrastructure concerns.
“Enhancing Network Security: The Role of Encryption Protocols in Secure Communication”
Classic Compute Resources
1. Predictable Performance
Classic compute resources offer predictable and dedicated performance. Users can create clusters with specific configurations tailored to their workloads. This predictability is advantageous for workloads that require consistent computational power and low-latency responses. Classic clusters are well-suited for scenarios where resources need to be pre-allocated and controlled to meet performance requirements.
From Repositories to CI/CD: GitHub vs. GitLab Breakdown
GitHub and Bitbucket: A Side-by-Side Analysis for Optimal Version Contro
DevOps and SRE: Two Methodologies, One Goal – A Comparative Study
WildFly vs. Tomcat: Choosing the Right Java Application Server
OpenCL vs. OpenGL: Understanding the Difference
2. Long-Running Workloads
Classic compute clusters are ideal for long-running or persistent workloads. They provide continuous availability and can be fine-tuned for specific use cases. This makes them suitable for tasks such as running production pipelines, hosting web services, or supporting real-time applications that require uninterrupted performance.
Here’s a comparison table highlighting the key differences between Serverless and Classic Compute Resources in the Databricks Lakehouse Platform:
| Aspect | Serverless Compute Resources | Classic Compute Resources |
|---|---|---|
| Resource Allocation | Automatically scales based on workload | Predefined clusters with fixed resources |
| Cost Model | Pay per usage (auto-scaling) | Pay for provisioned cluster resources |
| Infrastructure Management | Abstracted, minimal management | Manual provisioning and configuration |
| Elasticity | Highly elastic, ideal for fluctuating workloads | Fixed capacity, less elastic |
| Predictable Performance | Scalability may lead to variable performance | Predictable and dedicated performance |
| Ideal Use Cases | Ad-hoc, dynamic, and unpredictable workloads | Stable, long-running, and performance-critical tasks |
| Cluster Configuration | No need for cluster configuration | Requires cluster configuration and management |
| Use of Idle Resources | Efficient use of resources during idle periods | Resources may remain underutilized when idle |
| Setup and Deployment Time | Quick deployment and immediate availability | Setup time required for provisioning clusters |
| Maintenance and Scaling | Little to no maintenance; auto-scales as needed | Requires manual monitoring, scaling, and maintenance |
| Cost Efficiency | Potentially more cost-effective for sporadic workloads | Cost-efficient for continuous, stable workloads |
| Availability and Uptime | Instantly available; auto-scales for high availability | Dependent on cluster provisioning and configuration |
| Use Cases | Data exploration, development, and testing | Production workloads, data pipelines, web services |
| Management Overhead | Minimal infrastructure management overhead | Requires ongoing cluster management |
| Scalability for Bursty Workloads | Highly suitable for bursty, unpredictable workloads | May require over-provisioning for bursty workloads |
| Fine-Tuning Resources | Resource allocation auto-adjusts as needed | Fine-tuning cluster resources for specific requirements |
Remember that the choice between Serverless and Classic Compute Resources in the Databricks Lakehouse Platform should be based on your specific use case and workload requirements. Serverless is well-suited for dynamic and ad-hoc workloads, while Classic Compute Resources offer predictability and stability for long-running, performance-critical tasks.
In the Databricks Lakehouse Platform, the choice between serverless and classic compute resources depends on your specific use case and workload requirements. Serverless resources offer flexibility, cost-efficiency, and simplified management, making them well-suited for dynamic and ad-hoc workloads. On the other hand, classic compute resources provide predictable performance and are ideal for long-running, performance-critical tasks.
Understanding the differences between these two modes allows data teams to make informed decisions and leverage the Databricks Lakehouse Platform effectively to meet their data processing and analysis needs. Whether you prioritize flexibility or predictability, Databricks offers the tools and resources to help you unlock the full potential of your data.