Fog Computing vs. Edge Computing: A Comparative Analysis for Optimized Data Processing
In the ever-expanding world of technology, two terms often come up in conversations about decentralization and data processing efficiency: Fog Computing and Edge Computing. These two paradigms are changing the way we approach data processing and analytics at the edge of our networks. In this blog post, we will explore the fundamental concepts of Fog Computing and Edge Computing, their key differences, and how they are reshaping the landscape of modern computing.
Fog Computing: The Misty Middle Ground
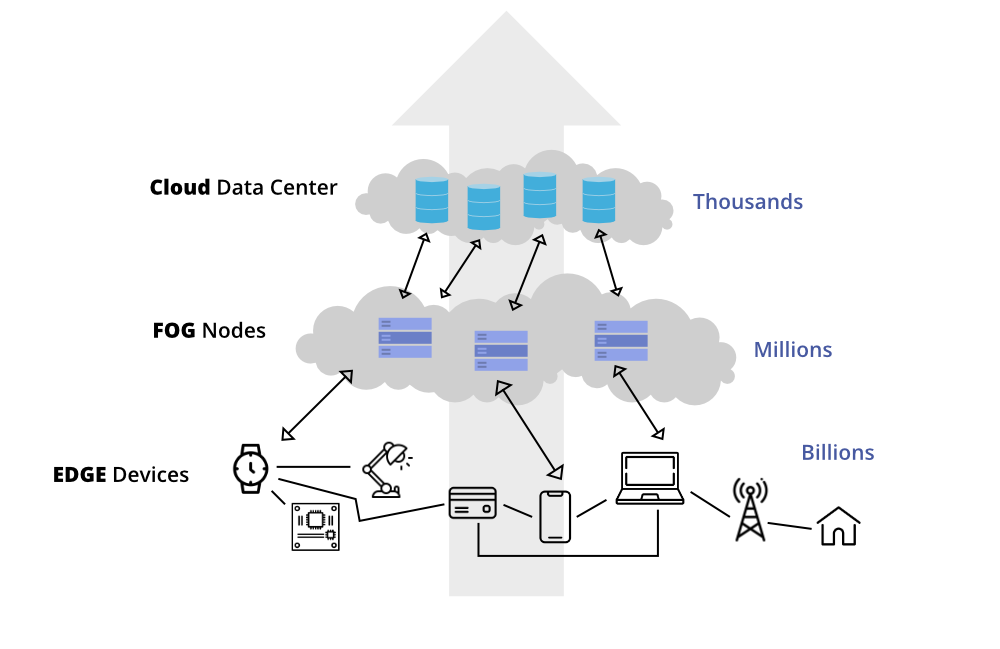
Fog Computing, sometimes referred to as “fogging,” is a distributed computing paradigm that bridges the gap between cloud data centers and the devices at the edge of a network. It extends cloud computing capabilities to the edge of the network and enables data processing closer to the data source. Here’s a breakdown of Fog Computing:
1. Data Processing Location: Fog Computing processes data at the network’s edge, typically in intermediary devices like routers, switches, and edge servers. This allows for reduced latency and faster response times for critical applications.
2. Use Cases: Fog Computing is well-suited for applications that require real-time or near-real-time processing, such as autonomous vehicles, industrial automation, and smart cities. It can offload processing tasks from the cloud, reducing the burden on centralized data centers.
3. Architecture: Fog Computing often uses a hierarchical architecture, where edge devices communicate with intermediary fog nodes, which in turn may communicate with the cloud. This hierarchy enables efficient data filtering and preprocessing.
Unleashing the Power of Cloud Computing: A Path to a Thriving Tech Career
Edge Computing: Pushing Boundaries to the Edge
Edge Computing, on the other hand, takes decentralization to the extreme by processing data directly on the edge devices themselves. It’s all about pushing computing resources as close to the data source as possible. Here’s a closer look at Edge Computing:
1. Data Processing Location: Edge Computing processes data right on the devices or “at the edge,” such as IoT sensors, smartphones, and industrial machines. This minimizes latency to the utmost degree.
2. Use Cases: Edge Computing is ideal for applications that demand ultra-low latency and high-speed processing, like augmented reality, virtual reality, and critical IoT applications, including predictive maintenance.
3. Architecture: Edge Computing uses a flat, decentralized architecture, where each edge device is self-sufficient and processes its data independently. This minimizes the need for continuous communication with a central hub.
Key Differences
Now, let’s highlight the key differences between Fog Computing and Edge Computing:
1. Processing Location: The primary distinction lies in where data processing occurs. Fog Computing happens at the network’s edge, while Edge Computing takes place directly on the edge devices themselves.
2. Latency: Edge Computing offers the lowest latency, making it ideal for applications where split-second decisions are critical. Fog Computing, although faster than traditional cloud processing, still introduces some latency due to its intermediary nodes.
3. Use Cases: Fog Computing is best suited for applications that require real-time processing but can tolerate a bit of latency. Edge Computing is for applications that require the absolute lowest latency possible.
4. Architecture: Fog Computing uses a hierarchical architecture, while Edge Computing opts for a flat, decentralized structure.
In the grand scheme of modern computing, both Fog Computing and Edge Computing play essential roles in optimizing data processing and analytics at the edge of our networks. Choosing between them depends on the specific requirements of your applications. Whether you’re in the realm of IoT, autonomous vehicles, augmented reality, or any other field, understanding the nuances of Fog Computing and Edge Computing will help you make informed decisions to ensure your systems run efficiently and responsively. As technology continues to evolve, these paradigms will continue to shape the future of computing.