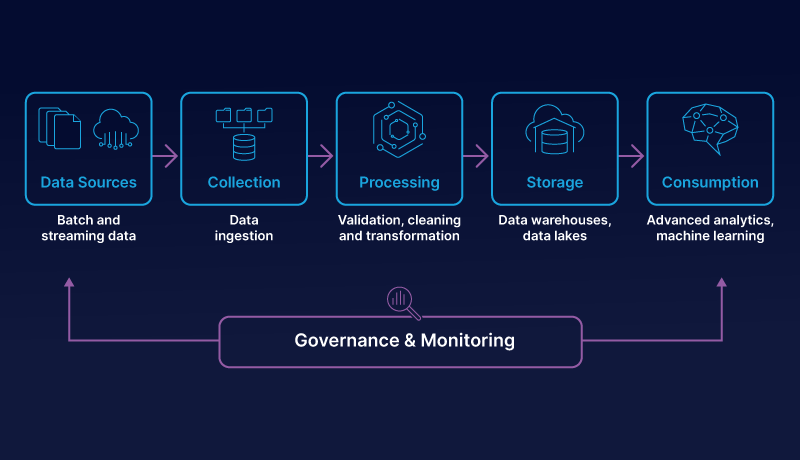
Best Practices for Designing Data Pipelines in Microsoft Fabric: Avoiding Common Mistakes
Microsoft Fabric has become an indispensable tool in the world of data management and analytics. Its pipeline copy activity feature is particularly noteworthy, allowing businesses to copy data from a source data store to a destination data store. However, to fully harness the power of this feature, it’s crucial to understand some best practices for designing data pipelines in Microsoft Fabric and avoid common mistakes.
Designing Data Pipelines for Simplicity
One of the key principles in designing data pipelines is simplicity. Reducing complexity wherever possible makes your pipelines easier to understand and maintain. This can be achieved by using labels and adhering to consistent naming conventions. Additionally, checking in your pipelines and using descriptive commit messages can help track changes and versions, enhancing the overall manageability of your data pipelines.
Testing Your Pipelines
Testing is a crucial aspect of pipeline design. Microsoft Fabric provides a preview button for this purpose, allowing you to test your pipelines frequently. Debug mode is another useful feature that lets you run your pipelines interactively and monitor the results. Validation activities can also be used to check the quality and consistency of your data, ensuring that your pipelines are functioning as expected.
Using Data Parameters Wisely
Data parameters are a powerful feature in Microsoft Fabric. They allow you to pass values between activities or pipelines, or to configure your pipelines dynamically. By using data parameters, you can avoid hard-coding values, reuse existing pipelines, or handle different environments. This flexibility can significantly enhance the efficiency and adaptability of your data pipelines.
Optimizing Your Pipeline Performance
Performance optimization is another critical aspect of pipeline design. Choosing the right source and destination settings, such as file format, compression, partitioning, and parallelism, can significantly improve your pipeline’s performance. Using staging tables or folders can also enhance data loading speed. Furthermore, tuning your copy activity settings, such as batch size, buffer size, and retry options, can help optimize your pipeline’s performance.
Monitoring and Troubleshooting Your Pipeline Runs
Microsoft Fabric provides monitoring tools that allow you to view the status, duration, and details of your pipeline runs. Using alerts and notifications can help you stay informed of any failures or issues. Logs and metrics can also be used to diagnose and resolve errors, ensuring that your pipelines are always running smoothly.
Avoiding Common Mistakes in Pipeline Design
While understanding best practices is crucial, it’s equally important to be aware of common mistakes to avoid when designing data pipelines in Microsoft Fabric. These include:
- Not considering data quality checks: Data quality is essential for ensuring the reliability and accuracy of your data analysis and insights. Implementing proper data quality checks in your data pipeline, such as validating, cleaning, normalizing, and enriching your data, is crucial.
- Not handling data drift: Data drift, the unexpected and unplanned change in the structure, format, or semantics of your data sources, can cause your data pipeline to fail or produce incorrect results. Design your data pipeline to be resilient and adaptable to data drift, by using schema-on-read, dynamic mapping, and error-handling techniques.
- Not optimizing your pipeline performance: Performance is a key factor for ensuring the efficiency and scalability of your data pipeline. Optimize your pipeline performance by choosing the right source and destination settings, such as file format, compression, partitioning, and parallelism, and tuning your copy activity settings, such as batch size, buffer size, and retry options.
- Not testing your pipeline: Testing is a crucial step for ensuring the functionality and correctness of your data pipeline. Test your pipeline frequently and thoroughly, using debug mode, preview mode, validation activities, and unit tests. Also, use version control and CI/CD tools to manage your pipeline development and deployment cycles.
- Not monitoring and troubleshooting your pipeline runs: Monitoring and troubleshooting are essential for ensuring the availability and reliability of your data pipeline. Monitor your pipeline runs using the monitoring tools in Microsoft Fabric, such as alerts, notifications, logs, and metrics. Troubleshoot any errors or issues using the troubleshooting tools in Microsoft Fabric, such as diagnostics, root cause analysis, and remediation actions.
In conclusion, designing effective and efficient data pipelines in Microsoft Fabric requires a thorough understanding of best practices and common pitfalls. By focusing on simplicity, regular testing, wise use of data parameters, performance optimization, diligent monitoring, and avoiding common mistakes, you can harness the full power of Microsoft Fabric’s pipeline copy activity. Whether you’re working with Microsoft Fabric and Snowflake, Microsoft Fabric Spark, or Microsoft Fabric Connectors, these best practices can guide you towards successful data management and analytics.