The Evolution from MapReduce to YARN: Empowering Flexible Data Processing in Hadoop
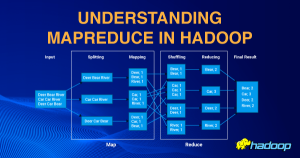
The Evolution from MapReduce to YARN: Empowering Flexible Data Processing in Hadoop The Apache Hadoop ecosystem has revolutionized the world of big data processing, enabling organizations to effectively store, process, and analyze massive amounts of data. One of the key components of Hadoop is MapReduce, a programming model and software framework that simplifies parallel … Continue reading The Evolution from MapReduce to YARN: Empowering Flexible Data Processing in Hadoop
0 Comments